Full-Gene Insights to Precision Drug Response
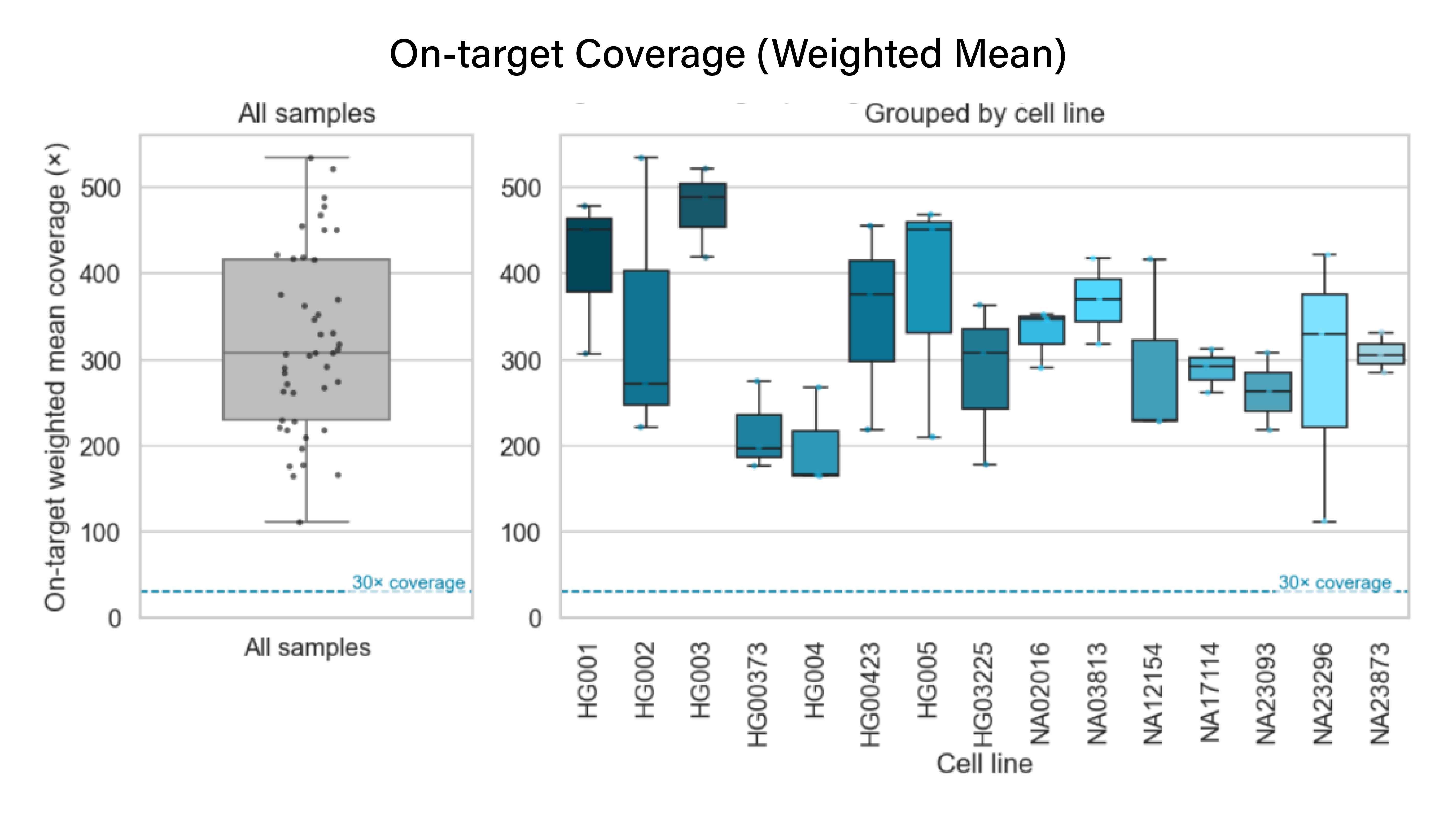
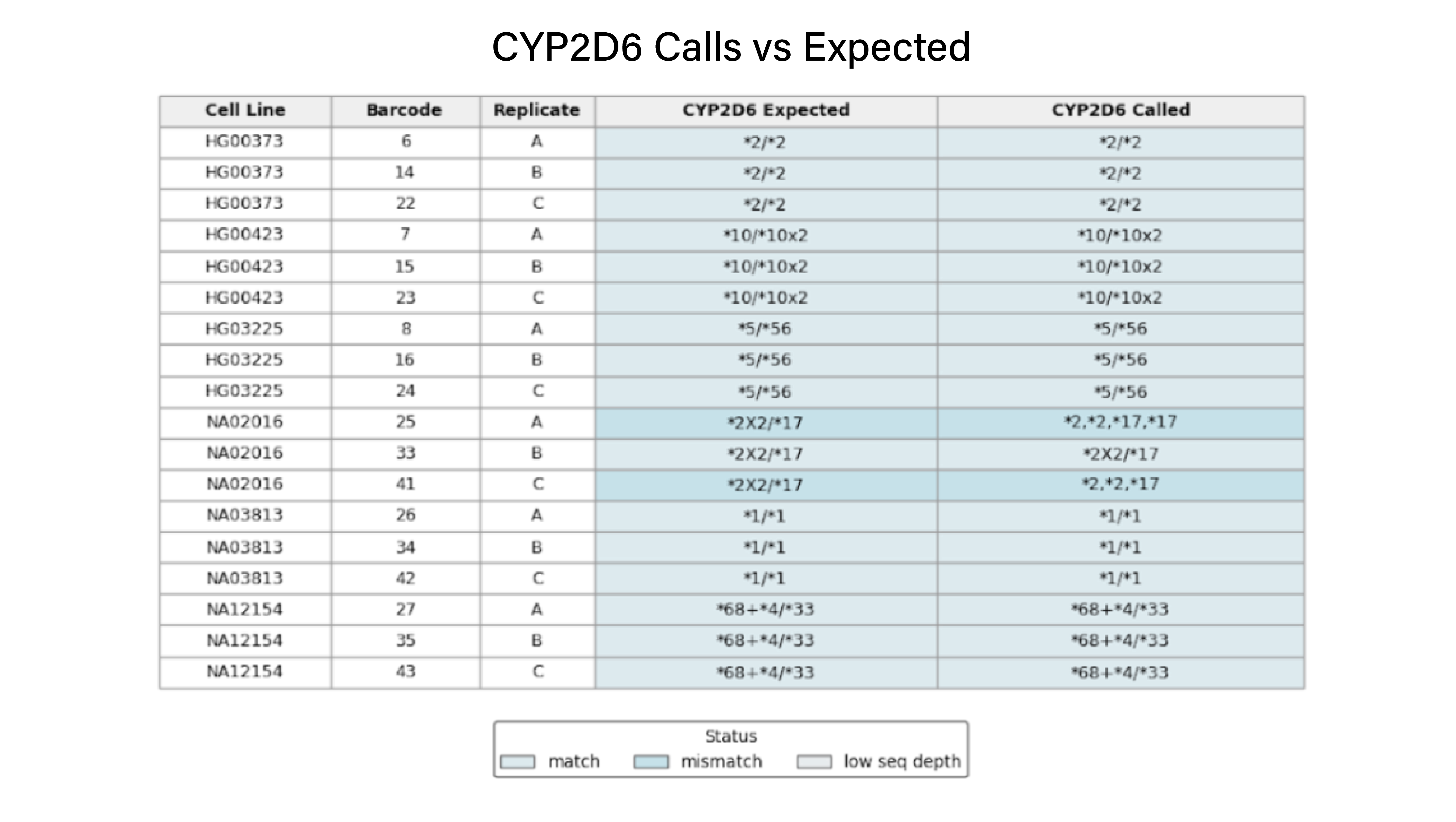
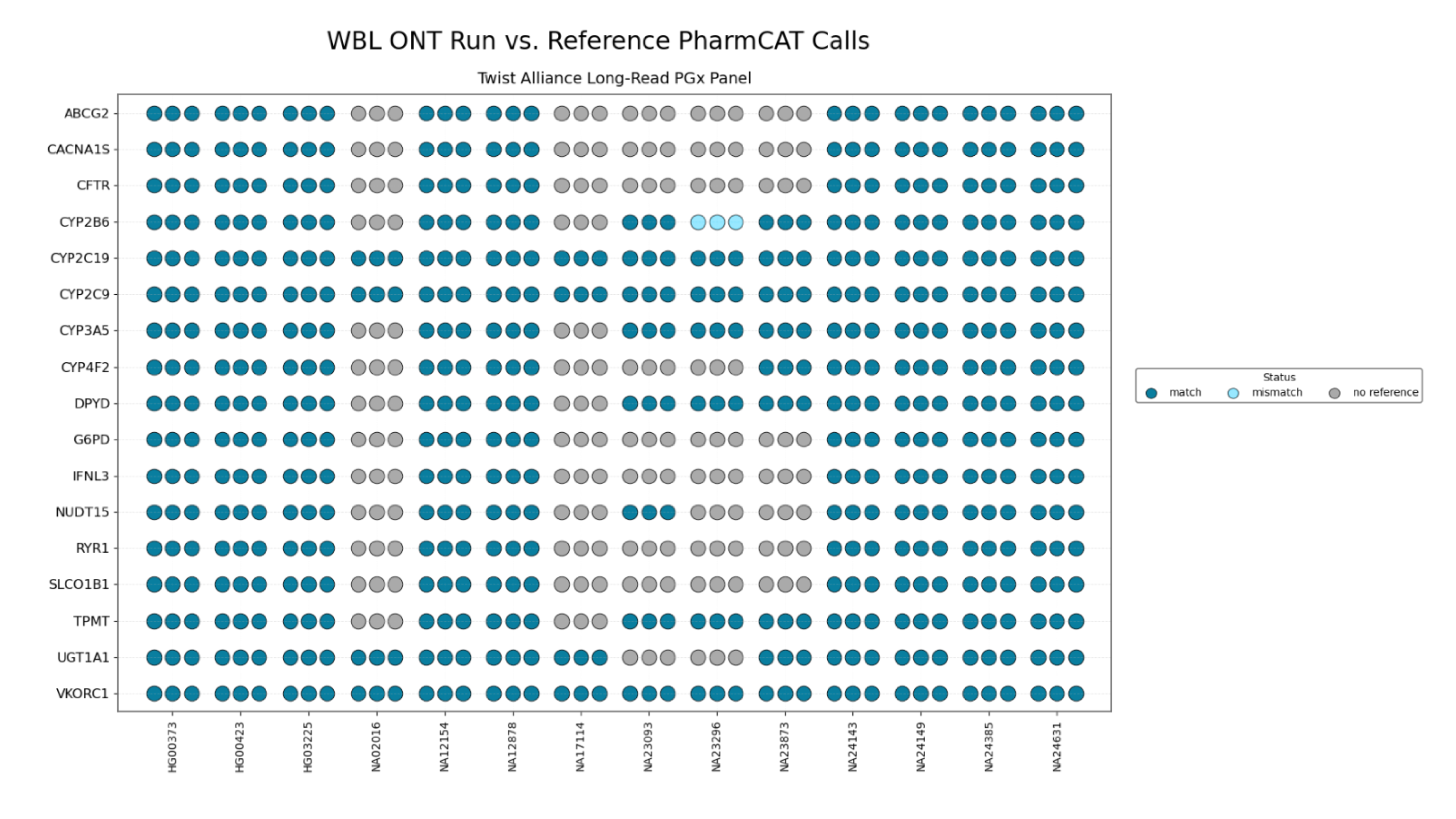
Wasatch BioLabs’ Pharmacogenomics (PGx) service delivers long-read, full-gene sequencing of 49 pharmacogenes, including UGT1A1, DPYD, and CYP2D6. Powered by Oxford Nanopore sequencing and Twist Bioscience target capture technology, our platform reveals complete haplotypes, copy number variants, and hybrid alleles directly from long-read DNA without short-read limitations.


.webp)